
Anthropic launched Opus 4.6 on Thursday, an update to its flagship Opus model that delivers major improvements over its predecessor—and many competitors—across virtually every benchmark.
Opus 4.6 also adds several useful new features, including a one-million-token context window, the ability to output up to 128,000 tokens, and agent teams in Claude code that can work on tasks in parallel.
Pricing remains the same as before: $5/$25 per million input/output tokens.
A step-change for enterprise users
The company argues that Opus 4.6 is a step change in using large language models (LLMs) for enterprise workflows, thanks to its ability to handle more complex tasks and deliver results faster.
As an Anthropic spokesperson tells The New Stack, “it gets much closer to production-ready quality on the first try than what we’ve seen with any model – documents, spreadsheets, and presentations will need less back-and-forth on iterations.”
Anthropic notes that Claude in Excel, for example, can now handle longer-running, more complex tasks and multi-step changes in a single pass.
Claude Opus 4.6 in PowerPoint (credit: Anthropic).
Benchmarks
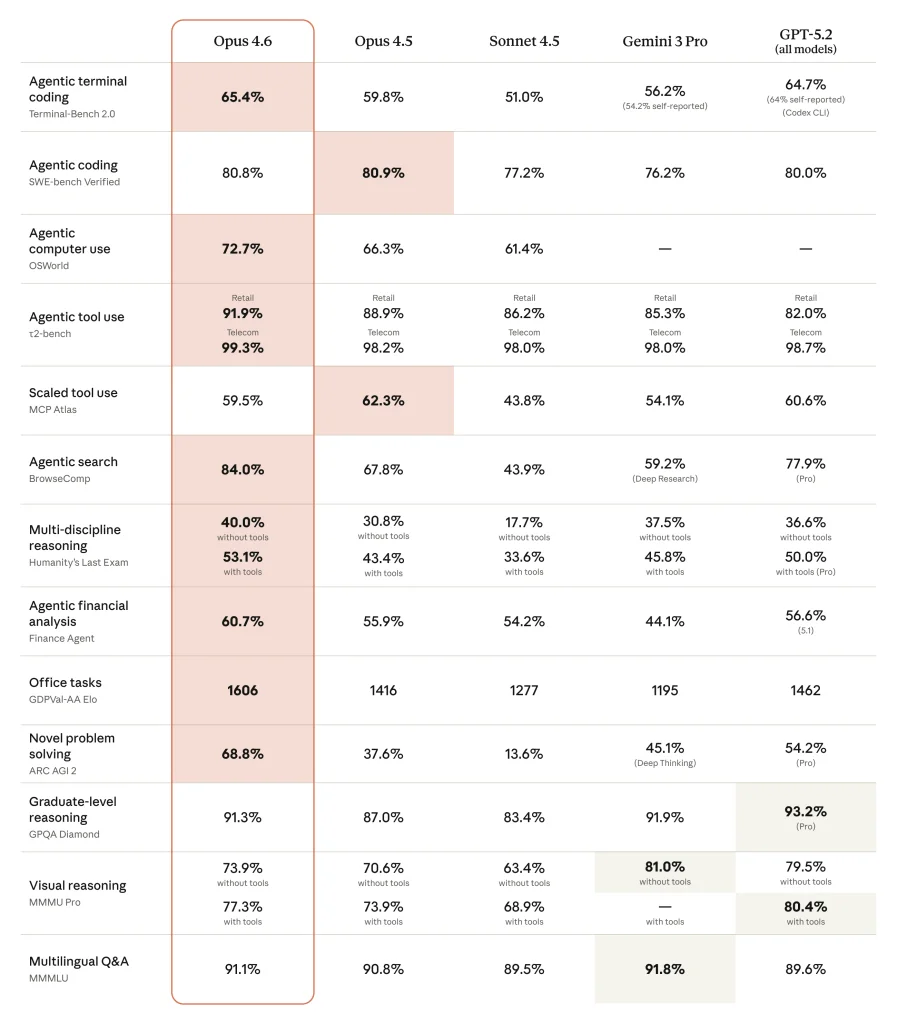
As has been the tradition for Anthropic models, Opus 4.6 once again improves on coding benchmarks, except for the SWE-bench verified tests and the MCP Atlas benchmark for testing tool usage, both of which show small regressions. That’s a bit of an anomaly, especially given that the model performs exceedingly well on similar benchmarks that examine agentic coding in the terminal (Terminal Bench 2.0) and agentic tool use (t2-bench).
On Terminal Bench, Opus 4.6 scores 65.4%, up from 59.8% for Opus 4.5, and on the OSWorld agentic computer use benchmark, its score rose from 66.3% to 72.7%. This now puts it ahead of OpenAI’s GPT-5.2 and Google’s Gemini 3 Pro, and according to Anthropic, the new model performs especially well at diagnosing more complex bugs.
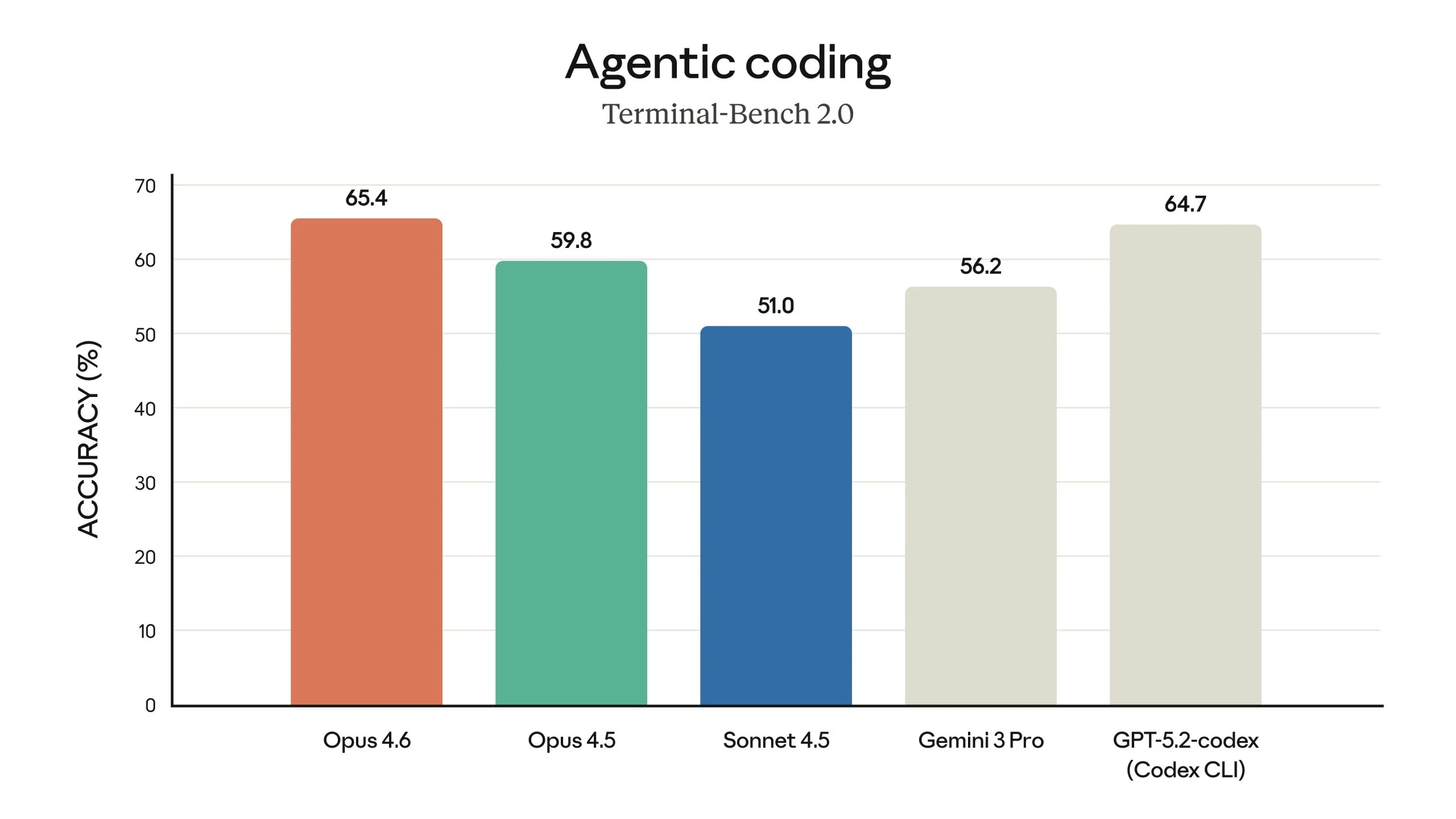
Claude Opus 4.6 Terminal Bench benchmark (credit: Anthropic).
Anthropic reports similar gains across benchmarks. The standout, though, is its score of 68.8% on the ARC AGI 2 benchmark, which is less about achieving PhD-level performance in specialized tasks and more about solving problems that are easy for humans and very hard for AI systems. Opus 4.5 scored only 37.6%, while Gemini 3 Pro scored 45.1% and GPT-5.2 scored 54.2%.
Benchmarks, of course, only tell some of the story and don’t always reflect how these models work in practice. Anthropic argues that, in its internal use, Opus 4.6 has handled far more challenging tasks, even without explicit instructions, and has done so more quickly and with better results.
In its safety evaluations, Anthropic found that Opus 4.6 matches Opus 4.5 in terms of misalignments such as deception, sycophancy, and encouraging user delusions.
More features
Even though the version number change is small, there are other updates here beyond improved reasoning performance. Opus 4.6 is the first model in the Opus family to feature a one-million-token context window, for example.
It’s also the first Anthropic model to use adaptive thinking, which allows it to consider contextual clues to determine how much effort to invest in a prompt. Developers still get more control over this with the /effort parameter to make explicit tradeoffs between quality, inference speed, and cost. Previously, though, the option was only to enable or disable extended thinking, so this now gives them a bit more control.
For API users, Claude can now use compaction to summarize context, allowing it to handle longer-running tasks without hitting its context limits.
There’s also a nod to digital sovereignty in this update. If your workloads can only run in the United States, that’s now an option, but you will pay 10% more for it. More typically, we see companies offer this for workloads that can’t run in the United States,
Agent teams
For developers, the most interesting new feature may be agent teams, though. While developers have found ways around this, by default, Claude Code has only run one agent at a time until now. Now, Anthropic is introducing agent teams, which allow developers to split work across agents. Those agents can then work in parallel and coordinate their efforts autonomously.
Anthropic notes that this is especially useful for read-heavy work, such as codebase reviews.
The post Anthropic debuts Opus 4.6 with standout scores for solving hard problems that other AIs miss appeared first on The New Stack.